Want to interact with LLMs (Large Language Models) but perplexed on how
to go about it and where to find good ones? You can of course interact with
LLMs via search engines, but what if you want to build your own interaction
agent? I got you covered in this article.
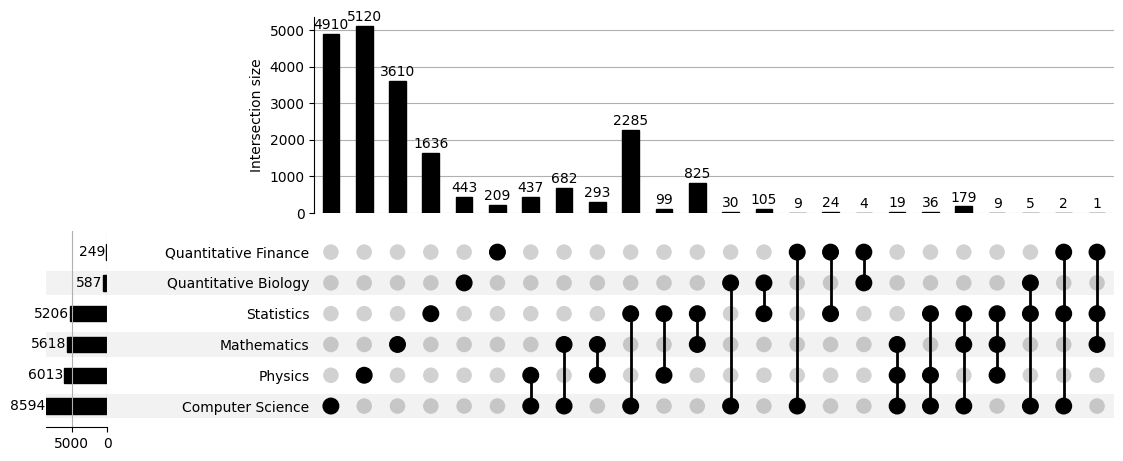
What broadly distinguishes one domain from another? It is the named entities.
It is essential to pick out entities from the text that you deal with for any
useful NLP/NLU task.
In your NLP and Machine Learning tasks, as also research, getting the
right detail from your voluminous text data is very important. You
need a convenient, programmatic interface to your textual data.
Using the right spellings shows good language skills. We often go wrong
with our spellings and need a way to correct them. An automatic tool
would help in this often overlooked task. North – a trie based spelling suggester helps you with some of your misspellings.
A template workflow with stable data trifurcation, custom loader with multi-level augmentation, CNN with variable learning rate and early stopping followed by the last mile decoding of the softmax output, and of course, evaluation.