Identify high impact categorical variables in classification datasets
414 words/2 min read
Classification datasets often have a number of categorical variables. There is
always the need to select the more important categorical variables for modelling,
especially in high-dimension datasets.
Listen – this blog post explained Often, classification datasets have a mix of continuous and categorical data. The continuous data typically have problems such as outliers, noise and lack of a defined distribution.
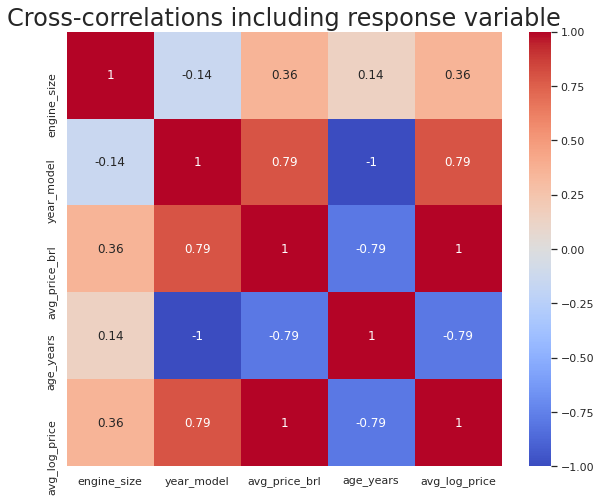
Heatmaps are used to visually represent correlation between various continuous features in a dataset. You can construct heatmaps and give them different colours for different values. This gives good visual appeal and makes it easier to understand.
Regression datasets often have a mix of categorical and continuous predictor
variables. When the number of categorical variables is large, how do you pick
the ones that are relevant to the regression(i.e. correlated to the response
variable)?
Most NLP projects require us to look at word counts in documents. The
traditional way is to draw histograms with vertical bars. But, are they
convenient?